外观
教程中只讲解大模型对话测试代码,逻辑较少,相对简单易懂,附件提供有全功能代码,可以自行了解。
项目方案
由于目前RKLLM暂不支持RK3566,所以目前我们没法通过RK3566的NPU部署大模型,
RKLLM仓库:https://github.com/airockchip/rknn-llm
本项目目前的方案是Vosk+Ollama+espeak-ng,完全依赖于RK3566的CPU运行
本项目不涉及设备树修改和系统编译,仅进行驱动移植适配,降低了复刻难度,但需要部分Linux知识
建议
硬件配置
- 因为本教程部分组件需要本地编译,所以这里推荐配置是4+32G EMMC
- 当然,如果你是1G/2G内存没关系,可以通过虚拟内存解决
- 如果你的EMMC硬盘是0G/16G也没关系,可以通过挂载外置TF卡解决
系统配置
- 系统这里支持Debian10/Ubuntu18/Ubuntu20或更高配置
- 推荐使用立创开发板提供的Ubuntu20.04镜像,其自带Python3.8和完整的软件包可跳过教程中部分编译操作
- Ubuntu20.04_20231130镜像下载链接
4.1 联网
本项目的控制环境为串口连接,开发板环境为Ubuntu20.04,同理支持Debian操作系统。这里选择使用Ubuntu20.04主要是系统环境相对较新,避免更新环境,当然你也可以选择其他的系统,教程也提供了环境编译教程。
4.1.1 连接WIFI
本项目不讲述系统安装步骤和开发板连接步骤,安装系统及连接开发板参考wiki.lckfb.com。
这里我们使用NetworkManager,使用nmcli命令连接WiFi(泰山派不支持5Ghz频段,确保你得WIFI是2.4Ghz),假设WIFI名称为EDA,密码为12345678,则命令如下:
sudo nmcli dev wifi connect "EDA" password "12345678"当输出成功用 "***" 激活了设备 "wlan0"时,WIFI连接成功
4.1.2 更新软件包
开始正式环境部署前,我们先更新同步软件包,确保所有软件包都是新的
sudo apt update这里推荐一个包管理器aptitude,它可以自动解决依赖关系,使用起来比较方便,安装命令如下:
sudo apt install -y aptitude
sudo aptitude update
sudo aptitude upgradeaptitude的基础用法很简单,将平常使用的apt换成aptitude就行,如sudo aptitude update
4.2 磁盘扩容
如果你是EMMC+TF卡配置,扩容完成后记得将TF卡挂载到系统,然后将教程中的模型及源码部分放置TF卡存储,避免占用系统盘空间
4.2.1 卸除挂载
删除开机自动挂载
这里我们将删除/oem和/userdata分区,然后扩容磁盘 先使用vim在/etc/fstab删除我们要删掉的分区,避免扩容后重启设备因找不到分区而进入紧急模式
sudo vim /etc/fstab找到以下行,按下i进入编辑模式,然后删除以下行
PARTLABEL=oem /oem ext2 defaults 0 2
PARTLABEL=userdata /userdata ext2 defaults 0 2编写完成后按下ESC,再按:wq!保存
接下来我们需要开始操作磁盘分区,确保你在/oem和/userdata已经没有重要数据 查看挂载
lckfb@linux:~$ df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/root 6G 2.8G 3.2G 46% /
devtmpfs 1.9G 8.0K 1.9G 1% /dev
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 2.0G 8.9M 1.9G 1% /run
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
tmpfs 2.0G 8.0K 2.0G 1% /tmp
tmpfs 391M 8.0K 391M 1% /run/user/1000
/dev/mmcblk0p7 123M 13M 104M 11% /oem
/dev/mmcblk0p8 52G 23K 52G 1% /userdata可以看到mmcblk0p7和mmcblk0p8这两个分区并不需要,也占用了很多空间
卸除当前挂载
sudo umount /dev/mmcblk0p7
sudo umount /dev/mmcblk0p8再次使用df -h查看是否移除挂载
4.2.2删除分区
查看分区
lckfb@linux:~$ lsblk
文件系统 容量 已用 可用 已用% 挂载点
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
mmcblk0 179:0 0 58.2G 0 disk
├─mmcblk0p1 179:1 0 4M 0 part
├─mmcblk0p2 179:2 0 4M 0 part
├─mmcblk0p3 179:3 0 64M 0 part
├─mmcblk0p4 179:4 0 64M 0 part
├─mmcblk0p5 179:5 0 32M 0 part
├─mmcblk0p6 179:6 0 6G 0 part /
├─mmcblk0p7 179:7 0 128M 0 part
└─mmcblk0p8 179:8 0 52G 0 part
mmcblk0boot0 179:32 0 4M 1 disk
mmcblk0boot1 179:64 0 4M 1 disk可以看到mmcblk0p7和mmcblk0p8分区还存在,我们需要删除掉,而其中mmcblk0p6是根目录分区,也就是我们扩容的目标分区
使用parted删除分区:
sudo parted /dev/mmcblk0 --script rm 7
sudo parted /dev/mmcblk0 --script rm 8提示报错,按要求重启sudo reboot
lckfb@linux:~$ sudo parted /dev/mmcblk0 --script rm 8
Error: Partition(s) 8 on /dev/mmcblk0 have been written, but we have been unable to inform the kernel of the change, probably because it/they are in use. As a result, the old partition(s) will remain in use. You should reboot now before making further changes.重启后再次查看分区,此时mmcblk0p7和mmcblk0p8应该已经被删除
lckfb@linux:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
mmcblk0 179:0 0 58.2G 0 disk
├─mmcblk0p1 179:1 0 4M 0 part
├─mmcblk0p2 179:2 0 4M 0 part
├─mmcblk0p3 179:3 0 64M 0 part
├─mmcblk0p4 179:4 0 64M 0 part
├─mmcblk0p5 179:5 0 32M 0 part
└─mmcblk0p6 179:6 0 6G 0 part /
mmcblk0boot0 179:32 0 4M 1 disk
mmcblk0boot1 179:64 0 4M 1 disk4.2.3分区扩容
安装扩容工具growpart
sudo aptitude install -y cloud-guest-utils使用growpart扩容磁盘
lckfb@linux:~$ sudo growpart /dev/mmcblk0 6
CHANGED: partition=6 start=360448 old: size=12582912 end=12943360 new: size=121782239,end=122142687
lckfb@linux-alip:~$ ^C
lckfb@linux-alip:~$ sudo resize2fs /dev/mmcblk0p6
resize2fs 1.44.5 (15-Dec-2018)
Filesystem at /dev/mmcblk0p6 is mounted on /; on-line resizing required
old_desc_blocks = 1, new_desc_blocks = 8
The filesystem on /dev/mmcblk0p6 is now 15222779 (4k) blocks long.使用 resize2fs 扩展ext4文件系统
lckfb@linux:~$ sudo resize2fs /dev/mmcblk0p6
resize2fs 1.44.5 (15-Dec-2018)
Filesystem at /dev/mmcblk0p6 is mounted on /; on-line resizing required
old_desc_blocks = 1, new_desc_blocks = 8
The filesystem on /dev/mmcblk0p6 is now 15222779 (4k) blocks long.验证,大功告成
lckfb@linux:~$ df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/root 58G 2.8G 53G 6% /
devtmpfs 1.9G 8.0K 1.9G 1% /dev
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 2.0G 8.9M 1.9G 1% /run
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
tmpfs 2.0G 8.0K 2.0G 1% /tmp
tmpfs 391M 8.0K 391M 1% /run/user/10004.3 扩容虚拟内存(低内存推荐)
4.3.1 创建SWAP交换文件
Debian部署需要编译,建议物理内存+虚拟内存容量大于等于8G,Ubuntu20.04部署不涉及编译,可以物理内存+虚拟内存容量大于等于4G,根据你的设备情况修改
sudo fallocate -l 4G /swapfile4.3.2 配置SWAP交换空间
按以下命令配置SWAP交换空间
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile4.3.3 设置开机自动配置
为了避免SWAP在重启后失效,我们可以在/etc/fstab中配置,这样当设备重启时,SWAP也会自动配置
使用vim在/etc/fstab添配置
sudo vim /etc/fstab在最底部添加以下行,按下i进入编辑模式
/swapfile none swap sw 0 0编写完成后按下ESC,再按:wq!保存就好了
4.3.4 验证
lckfb@linux:~$ free -h
total used free shared buff/cache available
Mem: 3.8Gi 215Mi 3.1Gi 23Mi 502Mi 3.5Gi
Swap: 4.0Gi 0B 4.0Gi4.4 环境部署
4.4.1 更新python版本
- Ubuntu20.04镜像可跳过此步骤
Debian镜像自带的Python3版本较老,这里我们使用本地编译安装的方法更新到python3.8.10。 编译安装需要较长的时间,但可以获得最好的兼容性稳定性
拉取源码编译安装
sudo apt update
sudo apt install -y build-essential libssl-dev libreadline-dev libsqlite3-dev wget
wget https://www.python.org/ftp/python/3.8.10/Python-3.8.10.tgz
tar -xvf python-3.8.10.tgz
cd Python-3.8
./configure --enable-optimizations
make -j$(nproc)
sudo make -j$(nproc) altinstall检测版本
linaro@linux:~/Python-3.8.10$ python3.8 --version
Python-3.8.10现在我们需要替换默认的Python3版本
sudo update-alternatives --install /usr/bin/python3 python3 /home/linaro/Python-3.8.10/python 1
sudo update-alternatives --config python3其中/home/linaro/Python-3.8.10/python依照自己的下载路径替换
4.4.2 Linux系统依赖安装
安装pip(Ubuntu20.04需要)
sudo aptitude install python3-pip安装 GPIO 库
sudo aptitude install -y python3-libgpiod安装pyaudio音频库
sudo aptitude install -y python3-pyaudio
sudo aptitude install -y portaudio19-dev安装Noto中文字库
sudo aptitude install -y fonts-noto-cjk安装 espeak-ng (TTS)
espeak-ng 是 espeak 的增强版,支持中文合成:
sudo aptitude install -y espeak-ng测试 espeak-ng
espeak-ng -v zh "你好,欢迎使用语音合成"安装 Ollama 框架
sudo aptitude install -y curl
curl -fsSL https://ollama.com/install.sh | sh安装 Ollama 框架(手动安装)
手动安装适用于下载速度较慢时使用,可以从电脑下载然后导入开发板中安装
sudo aptitude install -y curl
curl -L https://github.com/ollama/ollama/releases/download/v0.5.7/ollama-linux-arm64.tgz -o ollama-linux-arm64.tgz
sudo tar -C /usr -xzf ollama-linux-arm64.tgz4.4.3 Vosk编译
- Ubuntu20.04镜像可跳过此步骤
在Debian镜像上测试通过pip安装Vosk存在无法运行的情况,结合仓库Issues分析建议编译安装,所以这里我们选择编译Vosk所需的Kaldi。 - 整个编译需要较长时间,可能需要2-2个小时,可以先用tmux挂在后台运行。
安装编译工具
sudo aptitude update
sudo aptitude install -y git gfortran build-essential automake autoconf libtool
sudo aptitude install -y sox g++ libatlas-base-dev
sudo aptitude install -y libsndfile1-dev克隆仓库
git clone -b vosk --single-branch --depth=1 https://github.com/alphacep/kaldi
cd ./kaldi/tools编辑CMAKE
因为我们的ARM不支持msse优化,所以要关掉
sudo vim Makefile找到以下内容
ifeq ($(OSTYPE),cygwin)
openfst_add_CXXFLAGS = -g -O2 -Wa,-mbig-obj
else ifeq ($(OS),Windows_NT)
openfst_add_CXXFLAGS = -g -O2 -Wa,-mbig-obj
else
openfst_add_CXXFLAGS = -g -O3 -msse -msse2
endif修改成
ifeq ($(OSTYPE),cygwin)
openfst_add_CXXFLAGS = -g -O2 -Wa,-mbig-obj
else ifeq ($(OS),Windows_NT)
openfst_add_CXXFLAGS = -g -O2 -Wa,-mbig-obj
else
openfst_add_CXXFLAGS = -g -O3
endif编译Kaldi
sudo make -j $(nproc) openfst cub
sudo ./extras/install_openblas_clapack.sh
cd ../src
./configure --mathlib=OPENBLAS_CLAPACK --shared
make -j $(nproc) online2 lm rnnlm
cd ../..
git clone https://github.com/alphacep/vosk-api --depth=1
cd vosk-api/src
sudo make -j $(nproc)编译模块
cd ../vosk-api/python
python3 setup.py install4.4.3 Pip依赖安装
更新pip
python3 -m pip install --upgrade pip安装依赖库
sudo pip3 install ollama pyaudio pillow adafruit-circuitpython-ssd1306 Adafruit-Blinka安装vosk(Ubuntu20.04需要)
在Ubuntu20.04测试使用pip安装vosk可以正常运行,其他系统如果报错可以尝试前面进行编译安装
sudo pip3 install vosk4.5 模型部署
4.5.1 ASR模型部署
vosk模型安装
这里选择小模型,大模型很吃内存和CPU,不推荐
wget https://alphacephei.com/vosk/models/vosk-model-small-cn-0.22.zip
unzip vosk-model-small-cn-0.22.zip4.5.2 大语言模型部署
模型部署视内存大小确定,如果你的泰山派内存只有2G,推荐使用Qwen2:0.5B模型
安装DeepSeek:1.5B模型(2-4G内存推荐)
ollama run deepseek-r1:1.5b安装Qwen2:0.5B模型(1-2G内存推荐)
ollama run qwen2:0.5b4.6 驱动移植与适配
adafruit的驱动库并不支持泰山派,对此我们需要进行驱动移植适配
4.6.1 主板型号适配
adafruit的驱动库并不支持泰山派,对此我们需要进行主板型号识别适配
打开adafruit_platformdetect源文件,修改board.py文件
cd /usr/local/lib/python3.8/dist-packages/adafruit_platformdetect
sudo vim board.py大致在618行附件找到rk3566_id的版型识别,如下为其适配主板识别,因为是python代码,编程时注意对齐 按下i进入编辑模式
def _rk3566_id(self) -> Optional[str]:
"""Check what type of rk3566 board."""
board_value = self.detector.get_device_model()
board = None
#---------------在代码中添加以下内容-------------------------
if board_value and "lckfb tspi V10 Board" in board_value:
board = "LCKFB_TSPI"
#---------------------------------------------------------
if board_value and "LubanCat-Zero" in board_value:
board = boards.LUBANCAT_ZERO
if board_value and any(x in board_value for x in ("LubanCat1", "LubanCat-1")):
board = boards.LUBANCAT1
if board_value and "Radxa CM3 IO" in board_value:
board = boards.RADXA_CM3
if board_value and "Radxa ZERO 3" in board_value:
board = boards.RADXA_ZERO3
if board_value and "Radxa ROCK3 Model C" in board_value:
board = boards.ROCK_PI_3C
if board_value and "Rockchip RK3566 OPi 3B" in board_value:
board = boards.ORANGE_PI_3B
if board_value and "Hardkernel ODROID-M1S" in board_value:
board = boards.ODROID_M1S
elif "quartz64-a" in board_value.lower():
board = boards.QUARTZ64_A
return board编写完成后按下ESC,再按:wq!保存
4.6.2 GPIO适配
由于adafruit的gpio库并不支持泰山派,我们需要进行gpio适配 打开adafruit_blinka/board文件夹,这个文件夹存放着所有支持主板的GPIO定义,这里我们需要创建泰山派文件夹并创建泰山派的GPIO定义
cd /usr/local/lib/python3.8/dist-packages/adafruit_blinka/board/
sudo mkdir lckfb_tspi
cd ./lckfb_tspi
sudo vim lckfb_tspi.py这里我们用vim创建了一个python文件,在该文件中为泰山派GPIO定义名称就行 按下i进入编辑模式
from adafruit_blinka.microcontroller.rockchip.rk3566 import pin
# GPIO
GPIO0_B6 = pin.GPIO0_B6
GPIO0_B5 = pin.GPIO0_B5
GPIO1_A4 = pin.GPIO1_A4
GPIO3_B7 = pin.GPIO3_B7
GPIO3_C0 = pin.GPIO3_C0
GPIO3_A1 = pin.GPIO3_A1
GPIO3_C4 = pin.GPIO3_C4
GPIO3_A2 = pin.GPIO3_A2
GPIO3_A3 = pin.GPIO3_A3
GPIO3_A4 = pin.GPIO3_A4
GPIO3_A5 = pin.GPIO3_A5
GPIO4_C3 = pin.GPIO4_C3
GPIO4_C5 = pin.GPIO4_C5
GPIO3_A6 = pin.GPIO3_A6
GPIO4_C2 = pin.GPIO4_C2
GPIO4_C6 = pin.GPIO4_C6
GPIO3_A7 = pin.GPIO3_A7
GPIO3_B6 = pin.GPIO3_B6
GPIO3_B5 = pin.GPIO3_B5
GPIO3_B0 = pin.GPIO3_B0
GPIO3_C2 = pin.GPIO3_C2
GPIO3_C5= pin.GPIO3_C5
GPIO3_B1 = pin.GPIO3_B1
GPIO3_B2= pin.GPIO3_B2
GPIO3_C3 = pin.GPIO3_C3
GPIO0_B7 = pin.GPIO0_B7
GPIO3_B3 = pin.GPIO3_B3
GPIO3_B4 = pin.GPIO3_B4
# I2C
I2C2_SDA = GPIO0_B6
I2C2_SCL = GPIO0_B5
I2C3_SCL = GPIO3_B5
I2C3_SDA = GPIO3_B6
# UART
UART3_TX = GPIO3_B7
UART3_RX = GPIO3_C0
# SPI
MOSI = GPIO4_C3
MISO = GPIO4_C5
SCLK = GPIO4_C2
CS0 = GPIO4_C6编写完成后按下ESC,再按:wq!保存
4.6.3 适配Adafruit库
cd /usr/local/lib/python3.8/dist-packages
sudo vim board.py在26行找到版型判断的代码 按下i进入编辑模式
if board_id == ap_board.FEATHER_HUZZAH:
from adafruit_blinka.board.feather_huzzah import *
#---------------在代码中添加以下内容-------------------------
elif board_id == "LCKFB_TSPI":
from adafruit_blinka.board.lckfb_tspi.lckfb_tspi import *
#---------------------------------------------------------
elif board_id == ap_board.VISIONFIVE2:
from adafruit_blinka.board.starfive.visionfive2 import *编写完成后按下ESC,再按:wq!保存
4.6.4 适配IIC驱动
cd /usr/local/lib/python3.8/dist-packages/
sudo vim busio.py在154行左右可以找到问题出现的地方else
if detector.board.any_embedded_linux:
from adafruit_blinka.microcontroller.generic_linux.i2c import I2C as _I2C
if frequency == 100000:
frequency = None # Set to None if default to avoid triggering warning
elif detector.board.ftdi_ft2232h:
from adafruit_blinka.microcontroller.ftdi_mpsse.mpsse.i2c import I2C as _I2C
else:
from adafruit_blinka.microcontroller.generic_micropython.i2c import (
I2C as _I2C,
)这里的解决办法就是直接把上面的detector.board.any_embedded_linux的逻辑放到else中,修改后代码如下:
按下i进入编辑模式
if detector.board.any_embedded_linux:
from adafruit_blinka.microcontroller.generic_linux.i2c import I2C as _I2C
if frequency == 100000:
frequency = None # Set to None if default to avoid triggering warning
elif detector.board.ftdi_ft2232h:
from adafruit_blinka.microcontroller.ftdi_mpsse.mpsse.i2c import I2C as _I2C
else:
from adafruit_blinka.microcontroller.generic_linux.i2c import I2C as _I2C
if frequency == 100000:
frequency = None # Set to None if default to avoid triggering warning在26行找到版型判断的代码 编写完成后按下ESC,再按:wq!保存
4.7 程序编写
程序编写时可以根据自己需求进行修改,这里我们主要以语音识别和语音合成为例,进行程序编写
注意事项
1.尽量不要在代码中出现中文,如果出现中文,务必在代码头部添加以下内容,确保Python正确识别编码格式
# -*- coding: gbk -*-2.Python代码必须注意代码缩进和格式,如果缩进出现问题会导致程序无法正常运行
软件流程图
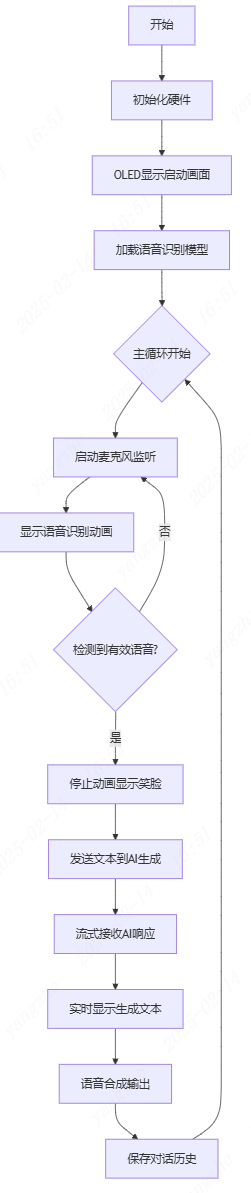
4.7.1 创建python代码及导入库文件
sudo vim ai.py按下i进入编辑模式
# -*- coding: gbk -*-
import time # 导入时间模块,用于控制延时
import vosk # 导入 Vosk 语音识别库
import json # 导入 JSON 解析库
import subprocess # 用于调用外部进程(如语音合成)
import ollama # 导入 Ollama,用于聊天 AI 处理
import asyncio # 导入 asyncio 以支持异步操作
import pyaudio # 导入 PyAudio 处理音频输入
import threading # 导入多线程模块
import re # 导入正则表达式模块,用于文本处理
from concurrent.futures import ThreadPoolExecutor # 用于异步任务的线程池
from board import * # 导入 board 库,用于 I2C 设备的引脚定义
import busio # 用于 I2C 通信
from PIL import Image, ImageDraw, ImageFont # 用于处理 OLED 显示图像
import adafruit_ssd1306 # 用于控制 SSD1306 OLED 屏幕一切开始前先导入我们需要使用的pip库
4.7.2 定义变量
# 选择合适的字体
font_path = "/usr/share/fonts/truetype/noto/NotoSansCJK-Regular.ttc" # OLED 屏幕显示的字体路径
font = ImageFont.truetype(font_path, 16) # 设置字体大小适应屏幕
# 初始化 I2C 设备
i2c = busio.I2C(I2C2_SCL, I2C2_SDA) # 通过 I2C2_SCL 和 I2C2_SDA 初始化 I2C 通信
disp = adafruit_ssd1306.SSD1306_I2C(128, 64, i2c) # 通过 I2C 初始化 128x64 分辨率的 OLED 屏幕
# 清空屏幕
disp.fill(0)
disp.show()
# 获取屏幕宽高
width = disp.width
height = disp.height
# 创建一个空白图像用于绘制
image = Image.new("1", (width, height))
draw = ImageDraw.Draw(image)
# 设置 Vosk 语音识别模型路径,根据自己的路径设置
model_path = "/home/linaro/vosk-model-small-cn-0.22"
model = vosk.Model(model_path) # 加载 Vosk 语音识别模型
recognizer = vosk.KaldiRecognizer(model, 16000) # 以 16kHz 采样率初始化语音识别器
# 记录会话历史
conversation_history = [
{"role": "system", "content": "你是嘉立创EDA-小嘉,是一个运行在泰山派上的离线本地大模型语音助手。"},
]
MAX_HISTORY_LENGTH = 1 # 限制会话历史的最大条数
asr_running = False # 语音识别时的动画状态控制变量这里还需要定义一些模型路径,字符路径等变量,这里为了避免内存超出,MAX_HISTORY_LENGTH限制会话最多保存1条,如果你设备内存或虚拟内存足够,可以增加。
4.7.3 OLED文本显示函数
def show_on_oled(text):
draw.rectangle((0, 0, width, height), outline=0, fill=0) # 清除屏幕
draw.text((0, 0), text[:8], font=font, fill=255) # 仅显示前8个字符
disp.image(image) # 更新屏幕内容
disp.show()屏幕显示这里进行了封装,确保每次显示前能自动清屏,同样的限制只能显示8个字符,避免超出显示长度。
4.7.4 动画表情绘制函数
def draw_face(mouth_state=0):
"""显示不同表情的脸部动画"""
draw.rectangle((0, 0, width, height), outline=0, fill=0) # 清空屏幕
# 绘制眼睛
draw.ellipse((32, 15, 40, 25), outline=255, fill=255) # 左眼
draw.ellipse((88, 15, 96, 25), outline=255, fill=255) # 右眼
# 嘴巴动画
if mouth_state == 0:
draw.line((50,50, 78, 50), fill=255, width=2) # 直线嘴巴
elif mouth_state == 1:
draw.arc((50, 40, 78, 60), start=0, end=180, fill=255) # 微笑嘴巴
elif mouth_state == 2:
draw.ellipse((58, 50, 70, 60), outline=255, fill=255) # 张嘴嘴巴
disp.image(image) # 更新屏幕内容
disp.show()动画表情直接利用库函数绘制圆和弧线实现
4.7.5 嘴巴动画
def asr_animation():
global asr_running
frame = 0
while asr_running:
draw_face(frame % 3) # 按 0、1、2 的顺序切换嘴巴形态
frame += 1
time.sleep(0.2) # 控制动画速度嘴巴动画通过该函数来控制变换,因为采用了多线程,可以避免动画影响Vosk识别语音
4.7.6 Vosk 语音识别
def recognize_speech(p):
global asr_running
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=20480)
stream.start_stream()
print("正在识别语音...")
asr_running = True # 启动动画
animation_thread = threading.Thread(target=asr_animation) # 创建动画线程
animation_thread.start()
try:
while True:
data = stream.read(2048, exception_on_overflow=False) # 读取音频数据
if recognizer.AcceptWaveform(data): # 处理音频流
result = recognizer.Result() # 获取识别结果
result_json = json.loads(result) # 解析 JSON 数据
if "text" in result_json:
text = result_json['text'] # 提取识别文本
print(f"识别到的文字: {text}")
asr_running = False # 停止动画
animation_thread.join() # 等待动画线程结束
draw_face(1) # 识别完成后显示微笑表情
time.sleep(1)
# 释放音频资源
stream.stop_stream()
stream.close()
return text
except IOError:
pass
# 释放资源
asr_running = False
animation_thread.join()
stream.stop_stream()
stream.close()我们先配置音频采样率16kHz,然后设置了一个20480帧的缓冲区大小(约1.28s),16位PCM格式。然后配置asr_running 全局标志用于控制动画线程运行,独立线程运行asr_animation实现非阻塞式用户体验。这里循环中启用流式传输,每次读取 2048 字节(约 128ms )实现非阻塞读取:exception_on_overflow=False 允许忽略缓冲区溢出错误,这样无需等待完整录音文件,实现边录边传。
4.7.8 保留中文字符
def clean_text(text):
return re.sub(r"[^\u4e00-\u9fa5,。!?]", "", text)由于我们使用的espeak-ng是轻量化的,只能支持一种语言,所以这里我们要过滤掉所以除中文外的文字和特殊符号。这里使用正则表达式"[^\u4e00-\u9fa5,。!?]"。正则表达式中的方括号表示字符集,^符号在开头表示取反,也就是匹配不在这个字符集里的任何字符。所以这个正则表达式的作用是匹配所有不属于指定Unicode范围的字符,以及标点符号,。!?。
4.7.9 模型处理
async def generate_and_play_text(input_text):
draw_face(1) # 显示微笑表情
time.sleep(1)
conversation_history.append({"role": "user", "content": input_text}) # 记录用户输入
response = ollama.chat(model="qwen2:0.5b", messages=conversation_history, stream=True) # AI 生成回答
generated_text = ""
for chunk in response:
if 'message' in chunk and 'content' in chunk['message']:
raw_text = chunk['message']['content']
clean_tts_text = clean_text(raw_text) # 清理文本
generated_text += raw_text
show_on_oled(raw_text)
print(f"当前生成: {generated_text}")
if clean_tts_text: # 确保有中文内容才播放
# 显示在 OLED 上
subprocess.run(['espeak-ng', '-v', 'zh', clean_tts_text]) # 语音朗读
conversation_history.append({"role": "assistant", "content": generated_text}) # 记录 AI 回应
draw_face(1) # 结束后显示微笑
time.sleep(1)这里就是将语音识别的文字传给Ollama然后交给模型处理,使用stream=True实现流式逐块生成,然后通过for chunk in response: if 'message' in chunk and 'content' in chunk['message']:典型的流式响应处理模式,主要用于处理流式返回的数据结构
4.7.10 主函数
async def main():
loop = asyncio.get_event_loop() # 获取事件循环
executor = ThreadPoolExecutor(max_workers=2) # 线程池用于并发任务
p = pyaudio.PyAudio() # 创建 pyaudio 实例
while True:
recognized_text = await loop.run_in_executor(executor, recognize_speech, p) # 识别语音
await generate_and_play_text(recognized_text) # 生成回答并朗读
p.terminate() # 释放音频资源
if __name__ == "__main__":
asyncio.run(main()) # 运行主程序这里max_workers=2 采用双线程实现动画和语音识别共同运行,互不干涉。然后通过pyaudio库用于输入音频数据,代入我们前面创建的函数中。
编写完成后按下ESC,再按:wq!保存
4.7.11 测试
如果一切正常,插入你的AI助手拓展版,当你使用以下命令,AI助手就开始工作了。如果有报错则按照报错修改,需要注意Python需要格式对齐,检测自己的代码修正格式。
sudo python3 ai.py4.8 配置自启动
4.8.1 创建systemd服务
我们需要把ai.python注册为系统服务,这样当设备开机时,就会自动运行我们的脚本。
sudo vim /etc/systemd/system/ai.service按下i进入编辑模式
[Unit]
Description=Run OLED AI Script on Startup
After=network.target
[Service]
ExecStart=/usr/bin/python3 /home/linaro/ai.py
WorkingDirectory=/home/linaro
Restart=always
User=root
[Install]
WantedBy=multi-user.target4.8.2 设置开机启动
为了能让设备在开机时自动运行,还需要激活服务,使用以下命令
sudo systemctl enable ai.service大功告成,你的AI助手打造好了!